Accurate 3D avatar from single 2D image:
Retrieve real human body measurements from virtual shape
Realized in 2022 Tags: Human-pose-estimation, body reconstruction, deep learning, 3D-avatar, neural network
 This project presents a simple way to generate a realistic virtual 3D avatar from one single 2D image.
This avatar maintains the body details like clothes and hair and accurate body shape proportions.
In fact, it is shown how it's possible to infer the original body measurements from the virtual ones.
This project presents a simple way to generate a realistic virtual 3D avatar from one single 2D image.
This avatar maintains the body details like clothes and hair and accurate body shape proportions.
In fact, it is shown how it's possible to infer the original body measurements from the virtual ones.
 Developed by researchers at Carnegie Mellon University, it can be considered the state-of-the-art approach
for real-time human pose estimation. It allows real-time localization of human body parts, such as the
shoulders, elbows, and ankles, from an input image or video.
Developed by researchers at Carnegie Mellon University, it can be considered the state-of-the-art approach
for real-time human pose estimation. It allows real-time localization of human body parts, such as the
shoulders, elbows, and ankles, from an input image or video.
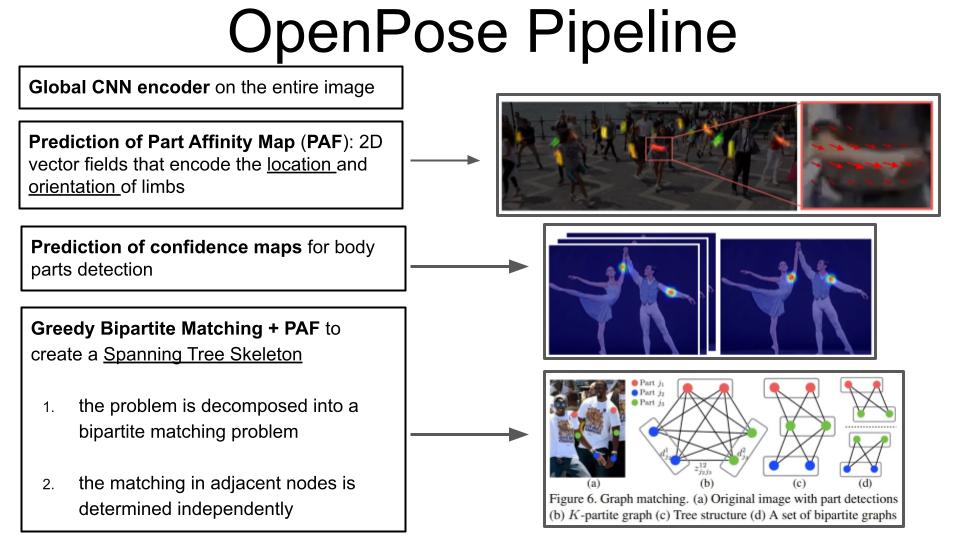 OpenPose uses a bottom-up approach, which means that the detection does not start from people's detections.
Instead, it starts from the key points detections. The key points are detected using a convolution-deep neural
network that encodes the entire image and produces an embedder. Then, another neural network uses this encoder
to produce a Part Affinity Field (PAF) that encodes the spatial relationship (location and orientation ) between
the human libs. Then, another neural network uses this PAF and the initial glob embedder to produce a confidence
map for the different body parts. At the end of these steps, the model is able to identify the different key
points on the body, but it is still necessary to build the Spanning tree to connect all the joints and build the
skeleton. This is done using the Greedy Bipartite graph algorithm that splits the problem into a bipartite matching
problem and then matches the adjacent nodes independently using the inferred PAF.
OpenPose uses a bottom-up approach, which means that the detection does not start from people's detections.
Instead, it starts from the key points detections. The key points are detected using a convolution-deep neural
network that encodes the entire image and produces an embedder. Then, another neural network uses this encoder
to produce a Part Affinity Field (PAF) that encodes the spatial relationship (location and orientation ) between
the human libs. Then, another neural network uses this PAF and the initial glob embedder to produce a confidence
map for the different body parts. At the end of these steps, the model is able to identify the different key
points on the body, but it is still necessary to build the Spanning tree to connect all the joints and build the
skeleton. This is done using the Greedy Bipartite graph algorithm that splits the problem into a bipartite matching
problem and then matches the adjacent nodes independently using the inferred PAF.
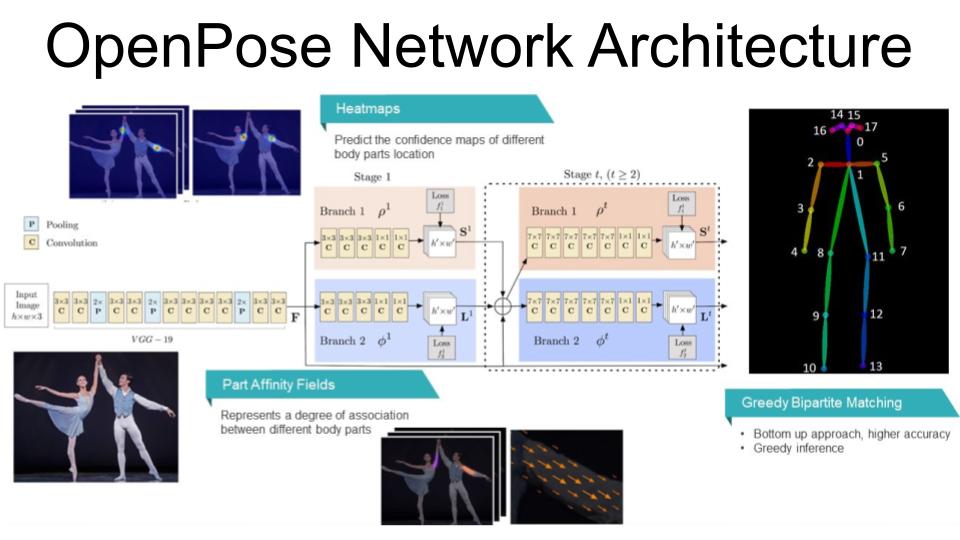 This is a general overview of the first version of the general network architecture. We can see how the
inference process is an iterative process, and the result is produced after a T number of iterations.
This is a general overview of the first version of the general network architecture. We can see how the
inference process is an iterative process, and the result is produced after a T number of iterations.
 This is the result of OpenPose applied to my own body.
This is the result of OpenPose applied to my own body.
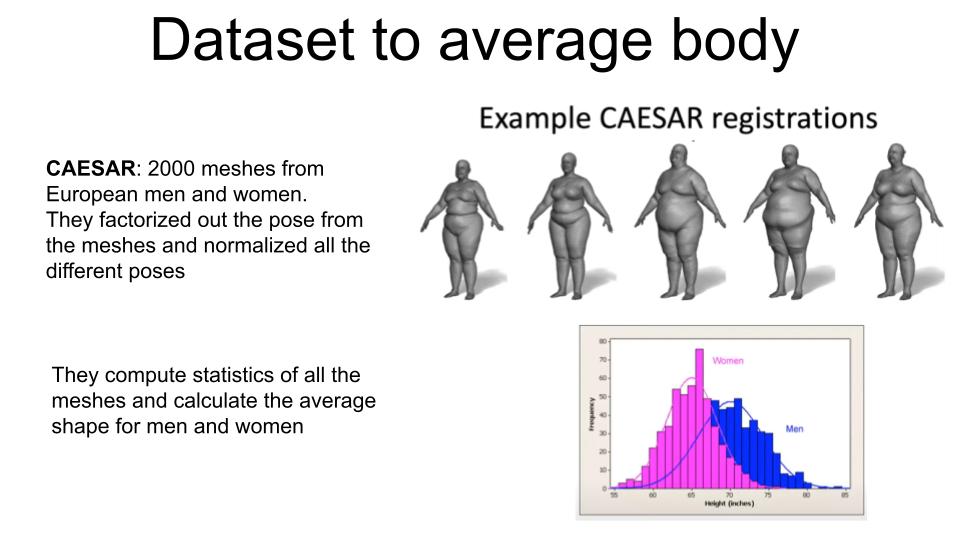
 SMPL is a method that reconstructs 3D human bodies from one or more RGB images by predicting
parameters of a statistical 3D body model.
SMPL is a method that reconstructs 3D human bodies from one or more RGB images by predicting
parameters of a statistical 3D body model.
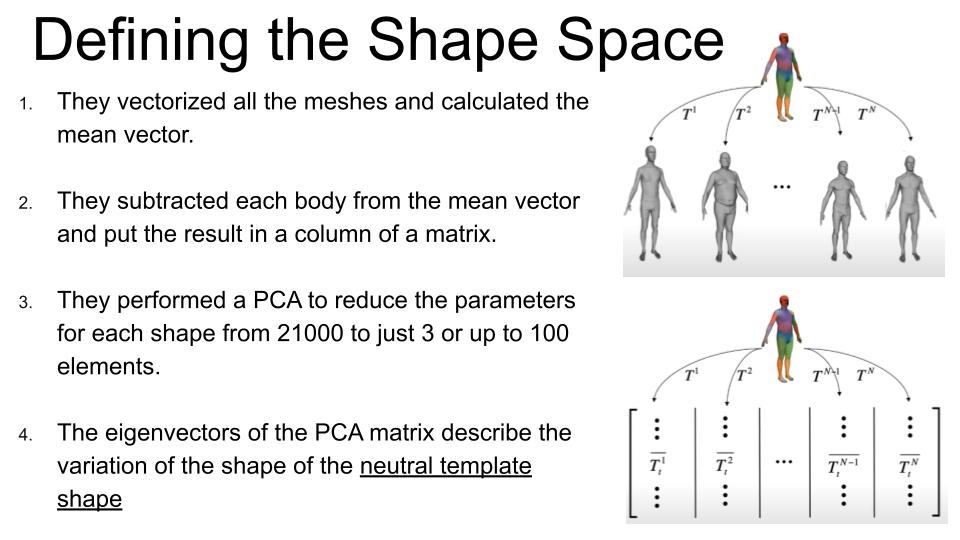
 Now that we have inferred a general template shape, we have to move the human mesh to a new pose.
This is called the Skinning process.
Now that we have inferred a general template shape, we have to move the human mesh to a new pose.
This is called the Skinning process.
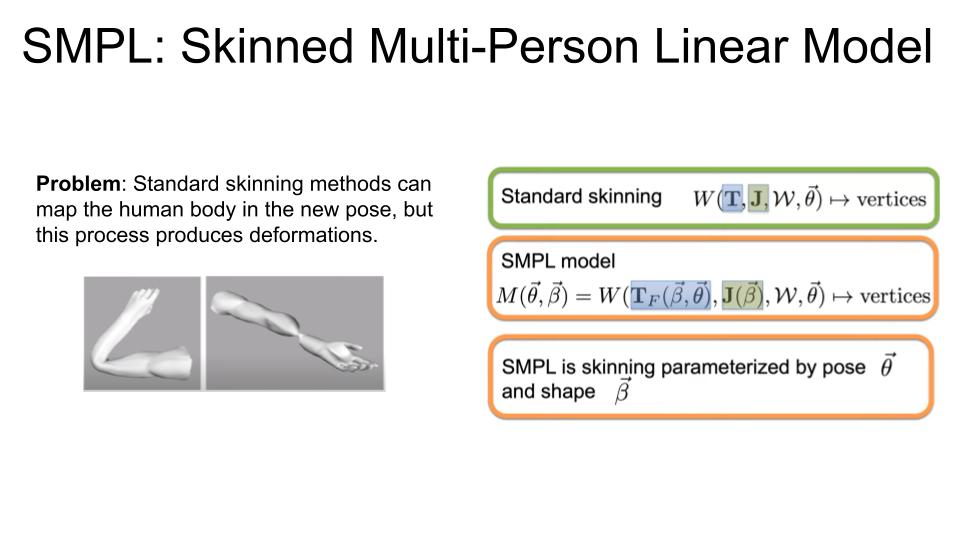 Standard skinning methods (based on the linear blend skinning (LBS) method) produce deformation on the final mesh produced.
Standard skinning methods (based on the linear blend skinning (LBS) method) produce deformation on the final mesh produced.
 SMPL algorithm produces a skinning result by a simple, additive process w.r.t general information learned by data.
SMPL algorithm produces a skinning result by a simple, additive process w.r.t general information learned by data.
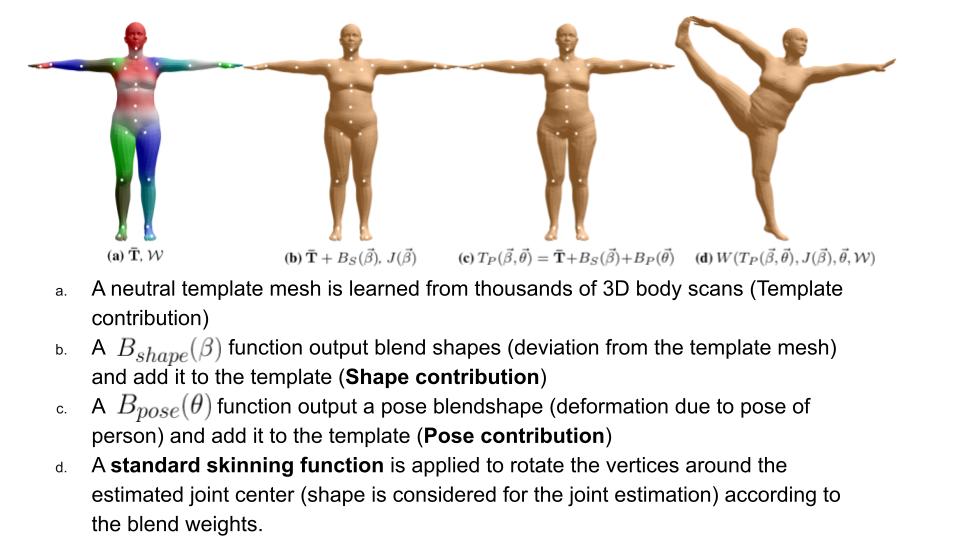 This is the detailed process.
This is the detailed process.

 This is the result of SMPL applied to my own body.
This is the result of SMPL applied to my own body.
 This work is an evolution of the previous SMPL model.
It is able to infer a more accurate body share during the body reconstruction and
also to infer from it the real body measurements. It can be used to estimate the
body size in the image.
This work is an evolution of the previous SMPL model.
It is able to infer a more accurate body share during the body reconstruction and
also to infer from it the real body measurements. It can be used to estimate the
body size in the image.
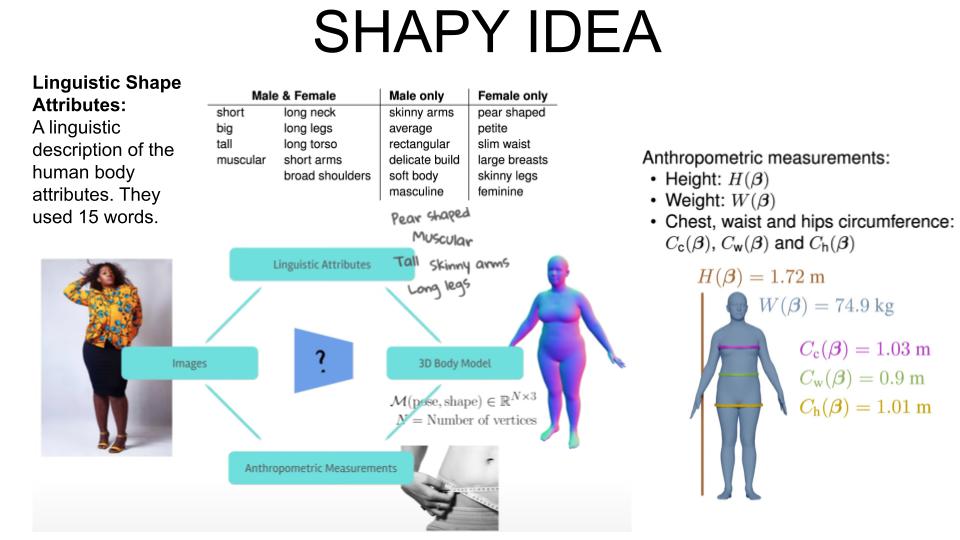 Since it is hard to collect pair images and relative meshes, SHAPY enriches the body
regressor information with external data like Linguistic Attributes and Anthropometric Measurements.
Since it is hard to collect pair images and relative meshes, SHAPY enriches the body
regressor information with external data like Linguistic Attributes and Anthropometric Measurements.
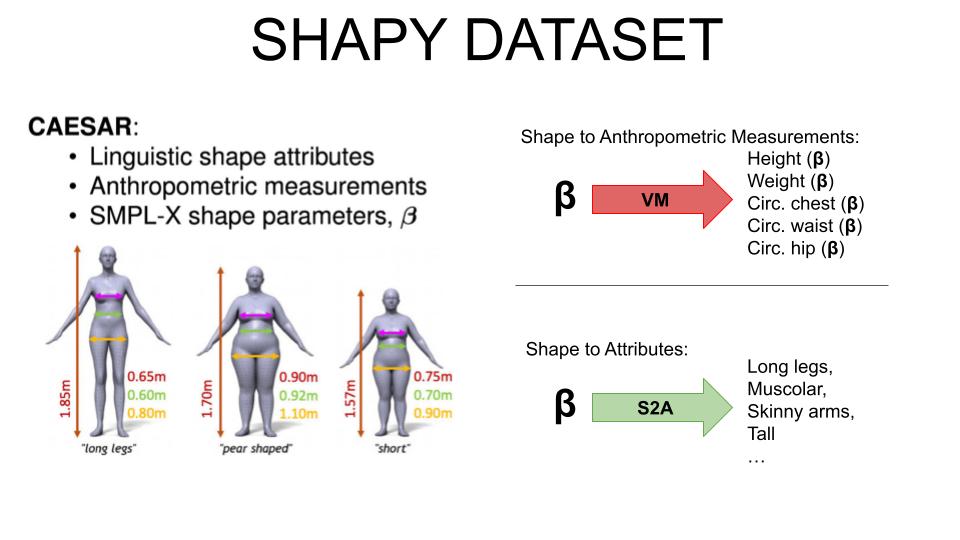 The labeled CAESER dataset with linguistic attributes and learned a Virtual Measurements model and Shape to Attributes model.
The labeled CAESER dataset with linguistic attributes and learned a Virtual Measurements model and Shape to Attributes model.
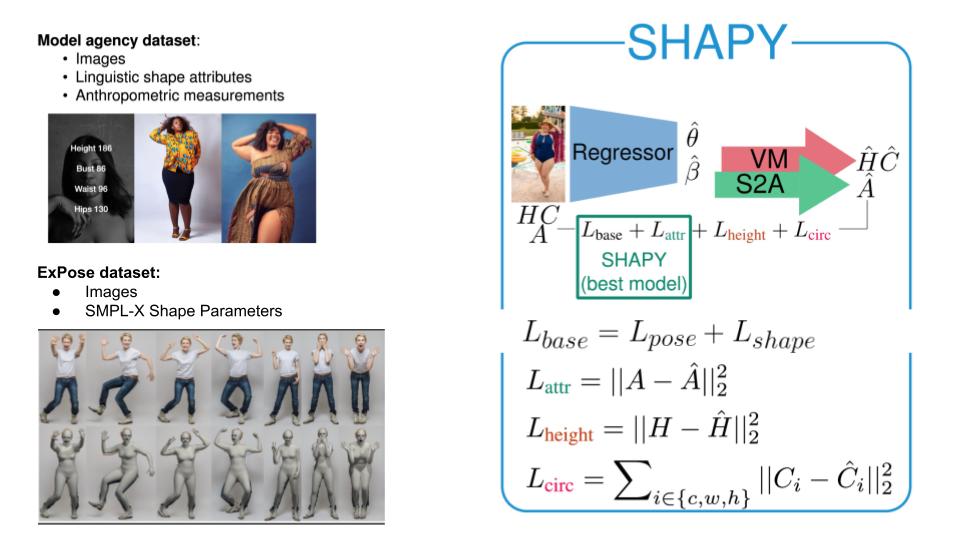 They add to the dataset new losses from the Virtual Measurements model and the Shape to Attributes model.
They add to the dataset new losses from the Virtual Measurements model and the Shape to Attributes model.
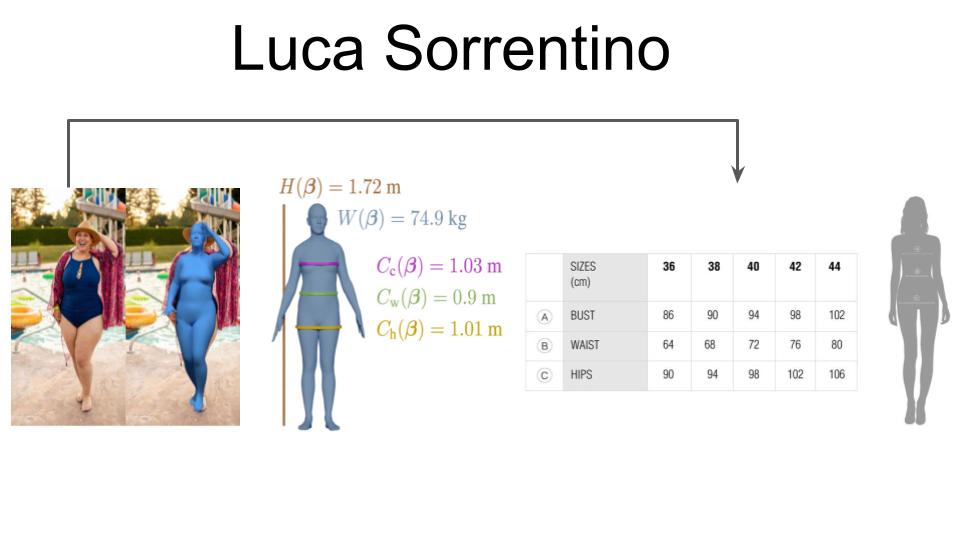
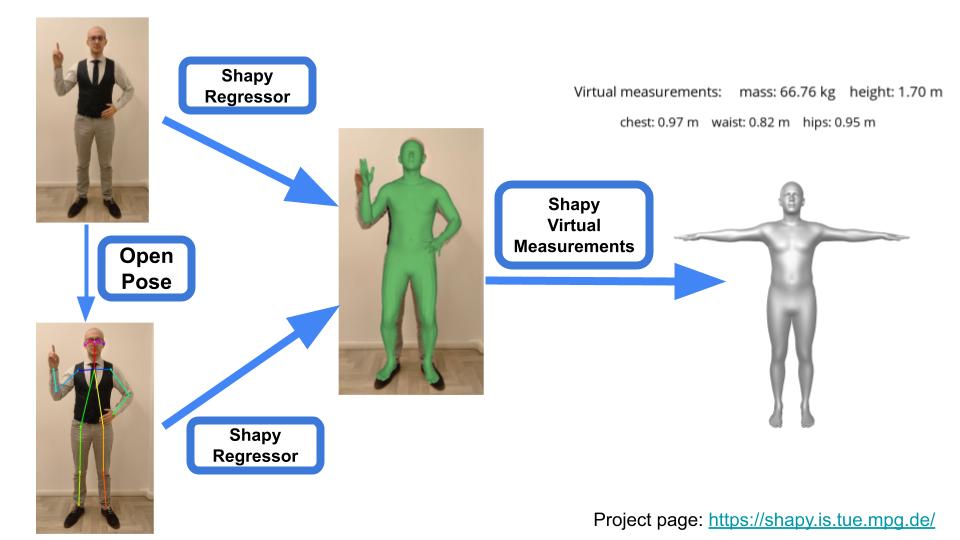 This is the result of SHAPY applied to my own body.
This is the result of SHAPY applied to my own body.
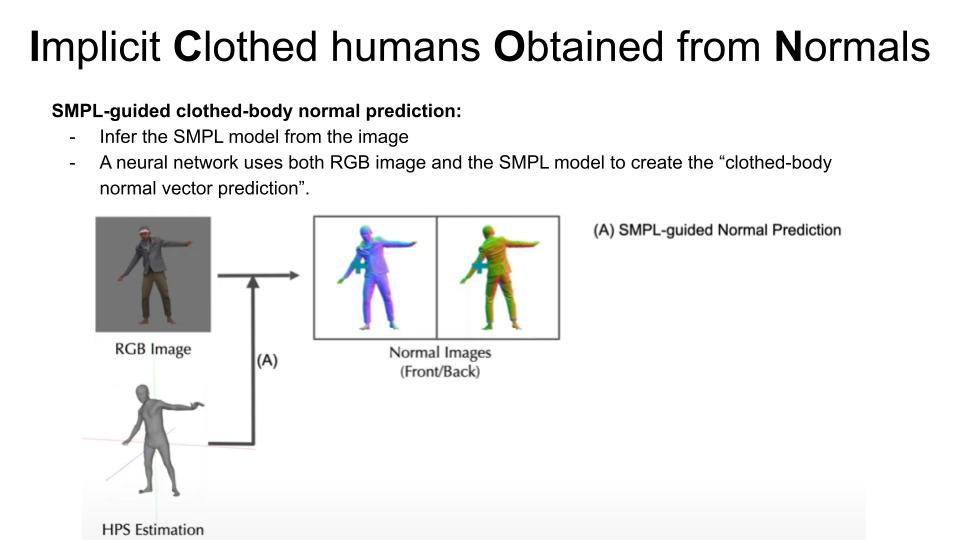
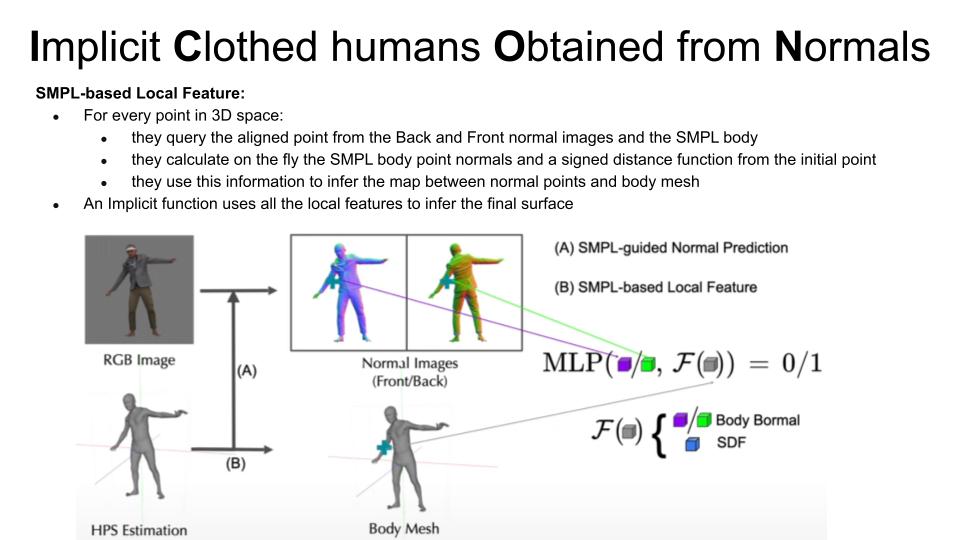
 Parametric models like SMPL can create a GENERAL human body but cannot reproduce specific details like clothes, hair …
ICON can create a detailed surface and maintain the ability to move the pose of the created avatar.
Parametric models like SMPL can create a GENERAL human body but cannot reproduce specific details like clothes, hair …
ICON can create a detailed surface and maintain the ability to move the pose of the created avatar.


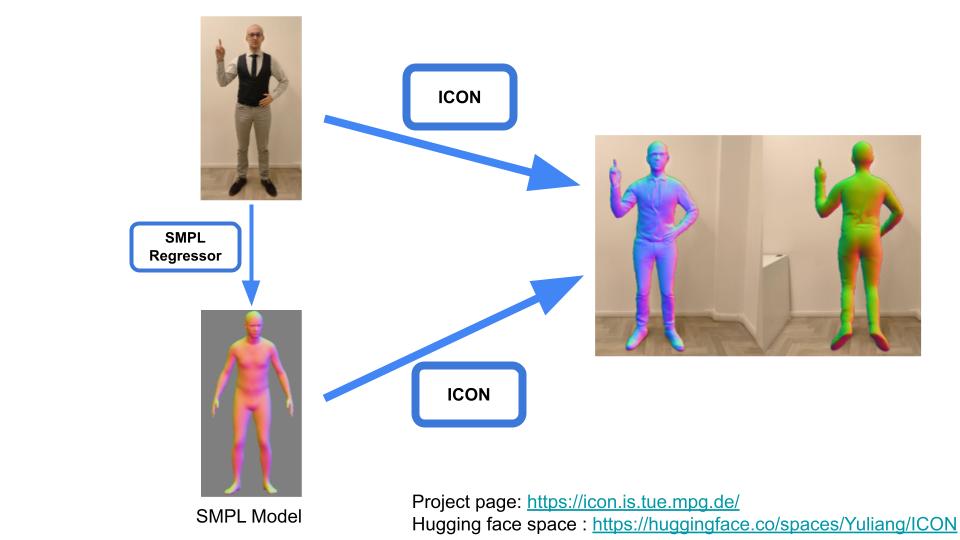 This is the result of ICON applied to my own body.
This is the result of ICON applied to my own body.

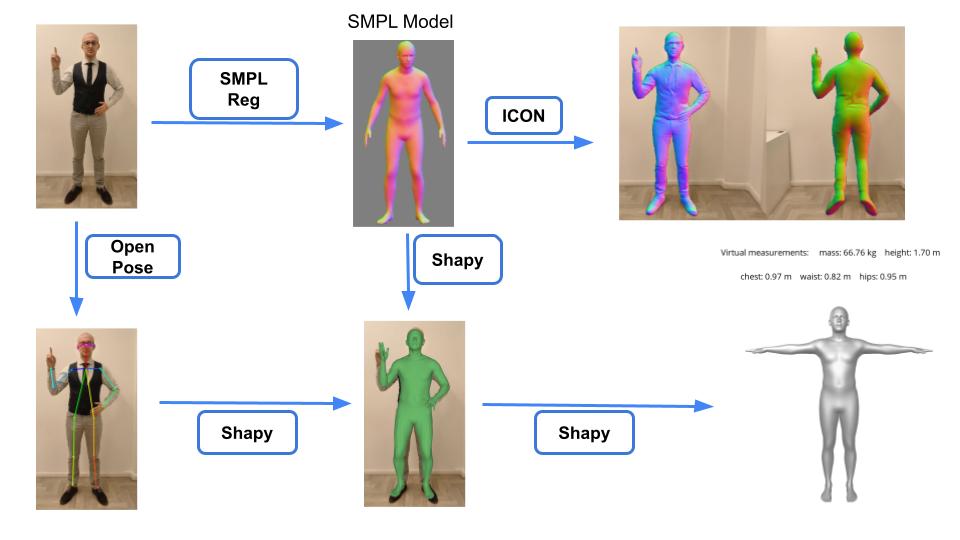 I use a combination of different models like OpenPose, SMPL, SHAPY, and ICON to create an accurate 3D model of my own body from a single 2D image.
I use a combination of different models like OpenPose, SMPL, SHAPY, and ICON to create an accurate 3D model of my own body from a single 2D image.
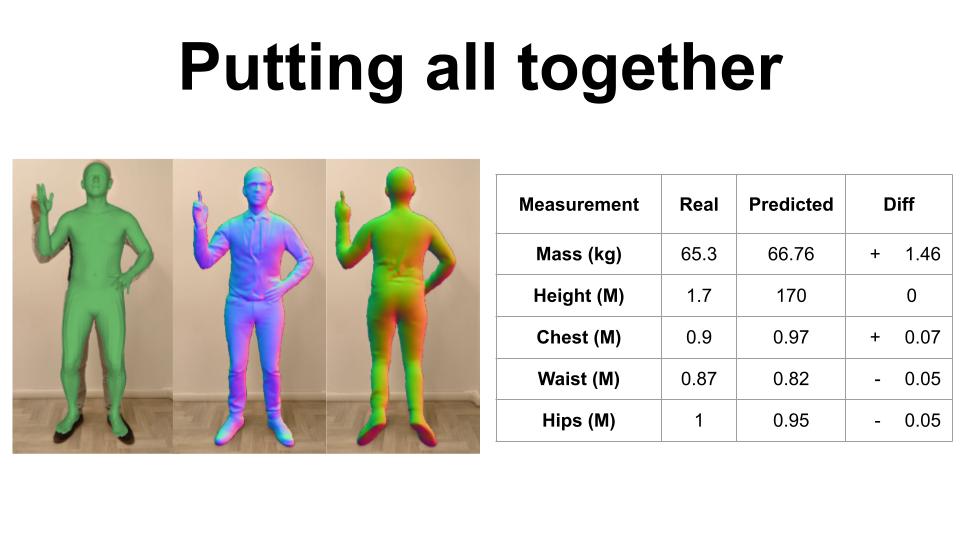 In this last slide, I show a comparison of my own body measurements with the ones inferred by the models.
In this last slide, I show a comparison of my own body measurements with the ones inferred by the models.
