ML Ops Tool:
make every experiment reproducicle
Realized in 2022
Tags: deep learning, mlops, dvc, wandb, hydra, git, docker, poetry
This is a list of tools and tips to create a fully reproducible experiments. Versioning the code
is not eought when we talk about reproducing a Deep Learning training. We also being able to
reproduce the environment, the data, and the exactly same parameters. In ordet to do that I pesent
some usefull tool like: code versioning (Git), data versioning (DVC), experiment logging and automatic
hyper-parameter tuning (Weight & Biases), configuration handler (Hydra), and portable environment
(Docker and Poetry).
This is a list of the tools included in this article:
- Data Version Control
- Hydra: Configuration Managare
- Poetry: Dependency manager
- Docker: Portable Machines
Data Version Control (DVC)
In real-world applications, you often don't work on a fixed data set but continue receiving new images and retraining models.
For this reason, it is essential to perform versioning of the dataset to be able to reproduce a training exactly.
Git is the perfect tool for code versioning but is not optimized for large files. For this reason, I use DVC https://dvc.org/
DVC is designed to make ML models shareable and reproducible. It is designed to handle large files, datasets,
machine learning models and metrics, as well as code.
You can find a great tutorial HERE!
Hydra: Configuration Managare
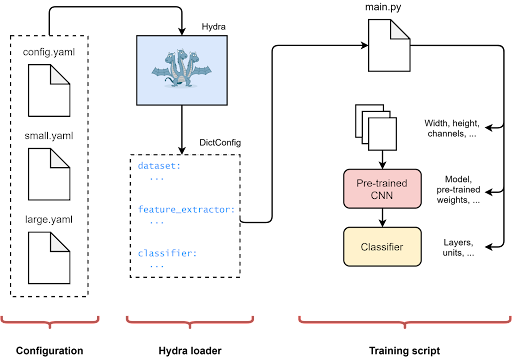
To be able to reproduce an experiment, running the same code is not enough. In fact, it is also necessary to provide
the same data set and parameters/configurations. For this reason, monitoring all parameters used in each experiment
must be a basic routine. A prevalent way to deal with this problem is to use the Yaml configuration, read them at the
beginning of the script, and if necessary, create a folder for the rerun and store the used configuration in that folder.
Initially, I created a special class to manage configurations, made with a singleton pattern to be easily imported and
used in each script. Then I discovered Hydra, produced by Facebook. Hydra is an open-source Python framework that
dynamically creates a hierarchical configuration based on composition and overwrites it via configuration files and the
command line.
You can find a great tutorial HERE!
Poetry: Dependency manager

Anaconda is an excellent tool for handling python virtual environments but is not suited for managing dependencies.
For example, it cannot make an automatic search of the most updated version of the package that does not produce
conflict with the others. For this reason, I use Conda to create the virtual env and POETRY for installing dependencies
and building the package easily. Poetry is a tool for dependency management and packaging in Python. It allows you to
declare the libraries your project depends on and it will manage (install/update) them for you. Poetry offers a lockfile
to ensure repeatable installs and can build your project for distribution.
You can find a great tutorial HERE!
Docker: Portable Machines
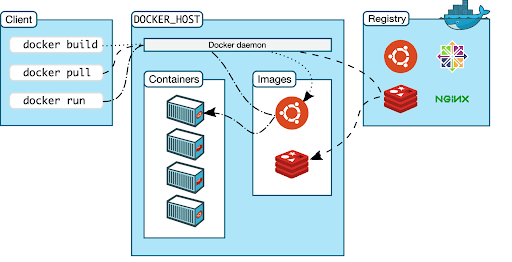
The last component is as famous as it is needed: docker. Once you have the list of Poetry dependencies, it might be a problem having
to reinstall all packages every time you deploy to a new machine. Furthermore, it is not certain that that machine has the same operating
system or other macro software components as the one on which the training was initially launched. A docker-based development allows
you to be abstract all these limits and create portable and always easily reproducible applications. Docker is an open-source software
platform to create, deploy and manage virtualized application containers on a common operating system (OS), with an ecosystem of allied tools.